


Our research focuses on integrating foundation models (FMs) with augmented reality (AR) to develop a more interactive and responsive driving assistance system. This project aims to leverage the multimodal perception and generation capabilities of FMs to interpret complex driver commands and provide real-time visual aids, such as traffic object identification and highlighting.
The system employ advanced data collection techniques using onboard sensors like Lidar and cameras, along with external sources such as high-definition maps and real-time traffic updates. This data will be processed through a multi-modal data fusion algorithm to create a cohesive understanding of the environment, enabling accurate 3D reconstruction and amodal tracking of objects.
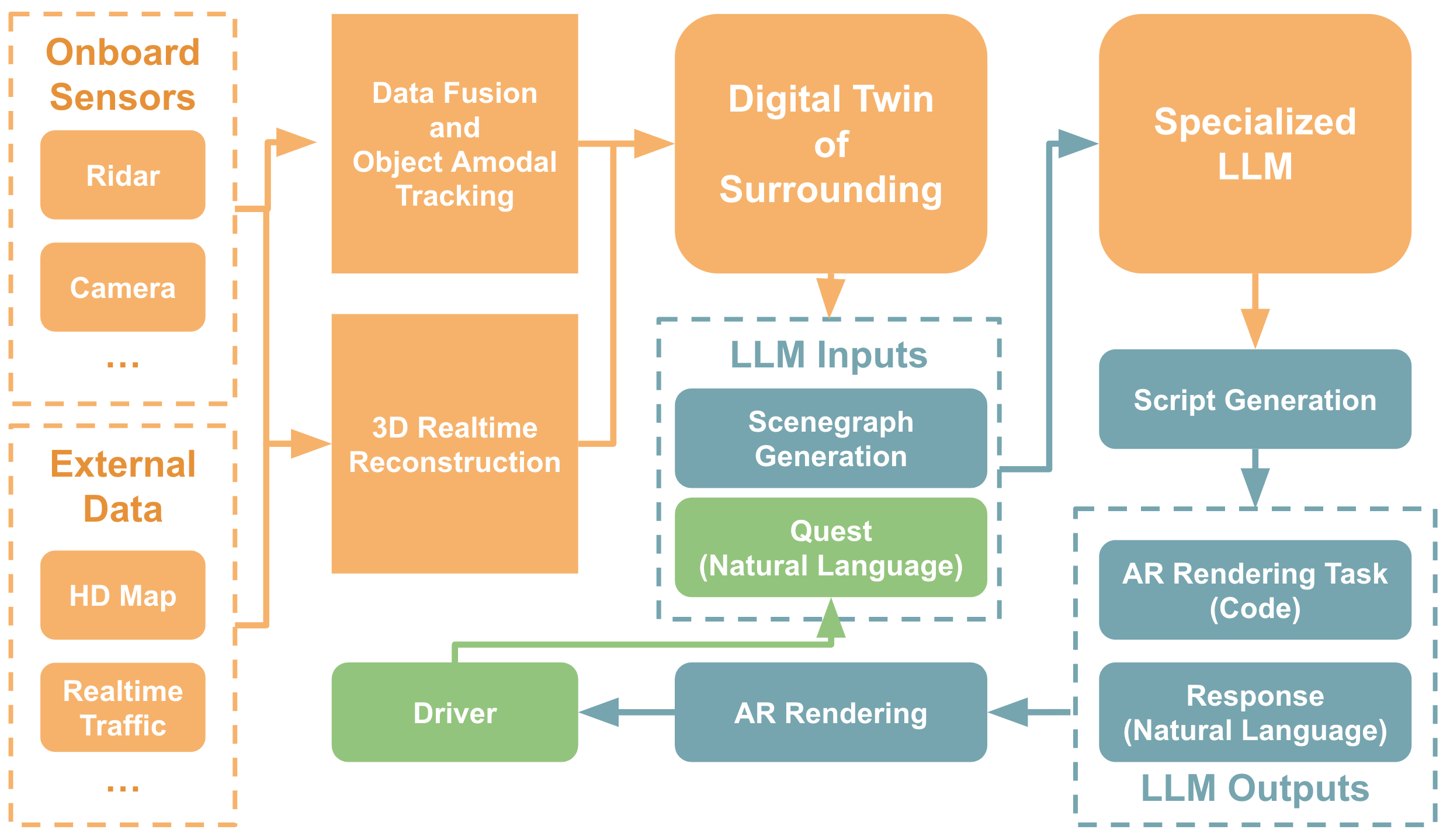
A key innovation in our approach is the use of a structured Scenegraph, proposed in previous work (GROMIT), to translate the complexity of the 3D world into a format understandable by FMs. This allows the system to process varied natural language commands and generate executable scripts for AR rendering tasks. A specialized large language model (LLM), trained on driving-related tasks, will interpret the Scenegraph and natural language queries to produce relevant scripts.
The system's design emphasizes adaptability through human-in-loop interactions, where drivers provide feedback in natural language. This iterative learning process allows the FM to refine its parameters and enhance its specialization in specific functionalities, improving the system's effectiveness over time.
